MXU (Matrix Multiply Unit)
The Matrix Multiply Unit (MXU) is the specialized computation core within a TPU’s TensorCore that performs highly efficient matrix multiplication operations.
Architecture
-
Systolic Array:
- 2D grid of arithmetic logic units (ALUs)
- TPU v2-v5: 128×128 (16,384 ALUs)
- TPU v6e: 256×256 (65,536 ALUs)
- Each ALU performs one multiply-add operation per clock cycle
-
Dataflow:
- Weights (RHS) flow from top to bottom
- Activations (LHS) flow from left to right
- Results accumulate and flow diagonally
Performance
- Operational Pattern: Performs one
bfloat16[8,128] @ bf16[128,128] -> f32[8,128]matrix multiplication every 8 clock cycles - Throughput:
- Precision Support:
- Native support for BFloat16 multiplication
- Support for INT8/INT4 with 2-4× higher throughput
- Results typically accumulated in FP32
Systolic Array Processing
The systolic array operates as a highly coordinated pipeline:
- Weights are loaded first, entering diagonally from the top
- Activations enter from the left, also in a diagonal pattern
- Each clock cycle, each ALU:
- Multiplies incoming activation with stored weight
- Adds result to accumulated value from upstream
- Passes result downstream
- Results exit from the bottom or right edge of the array
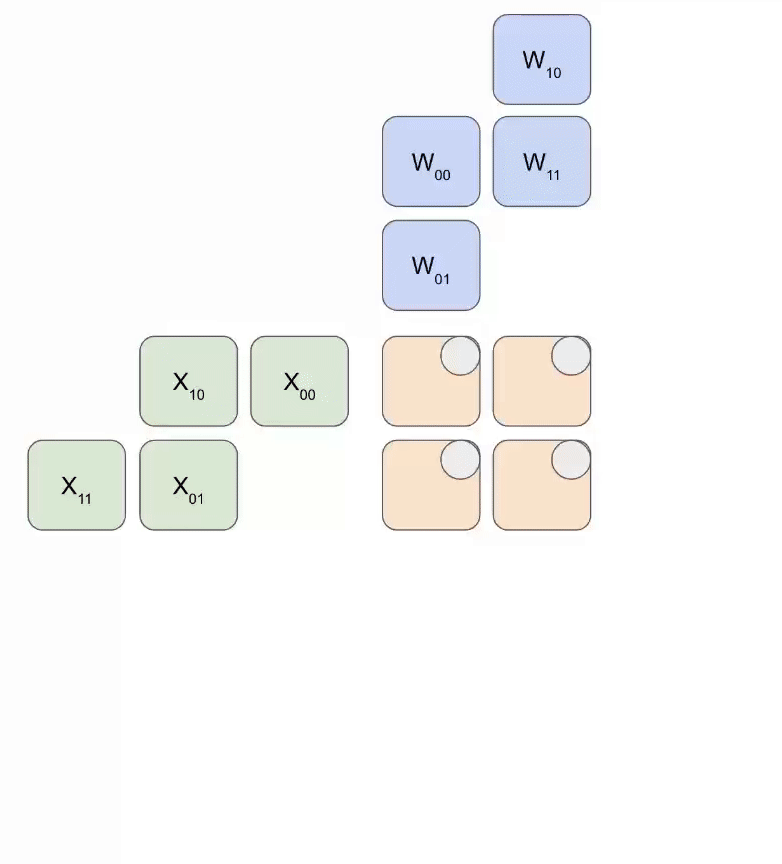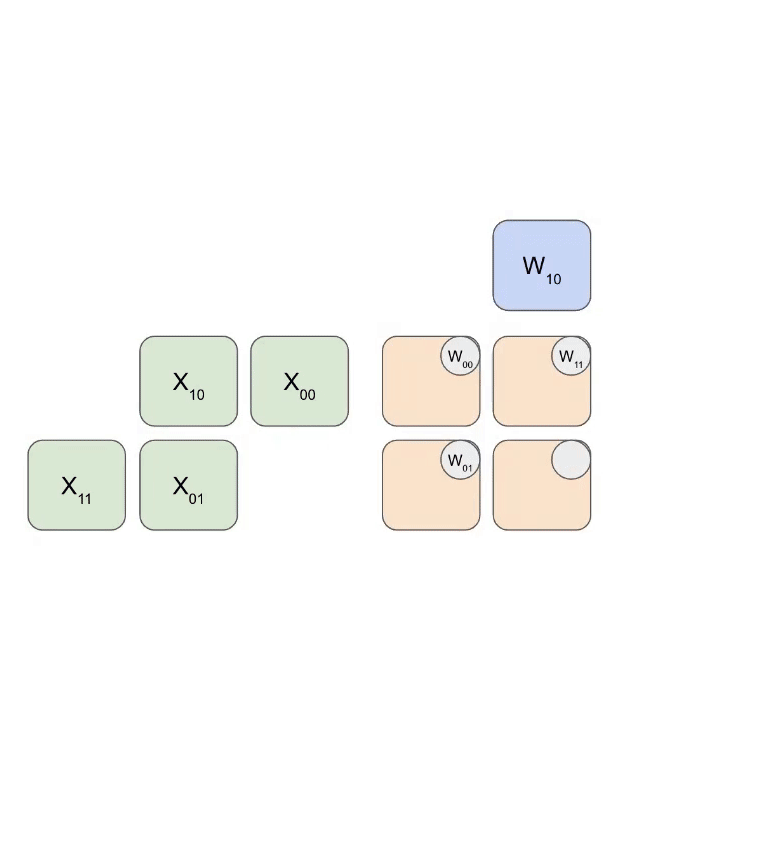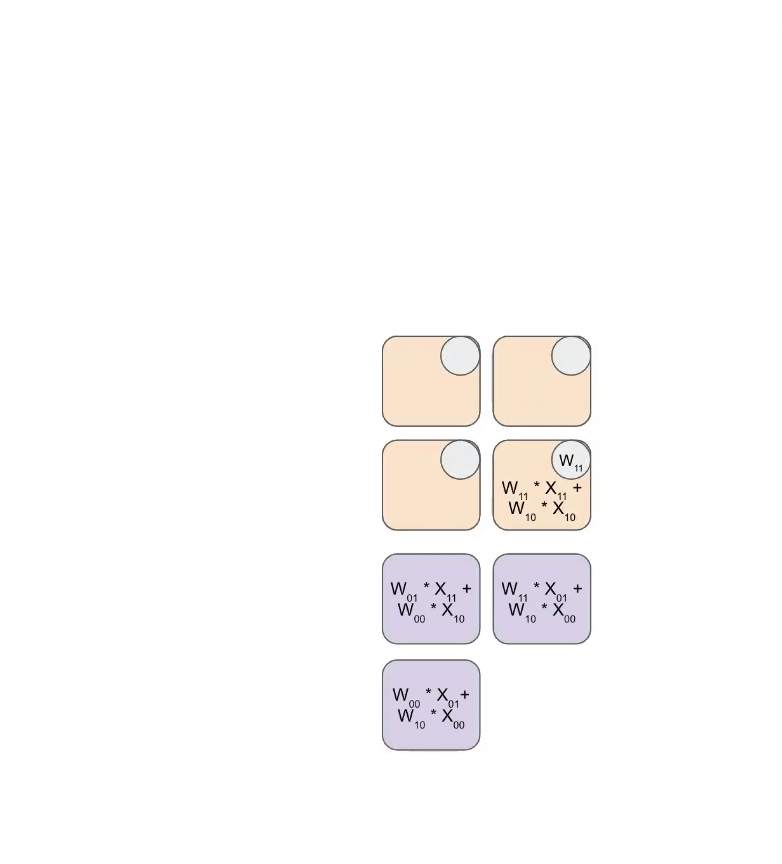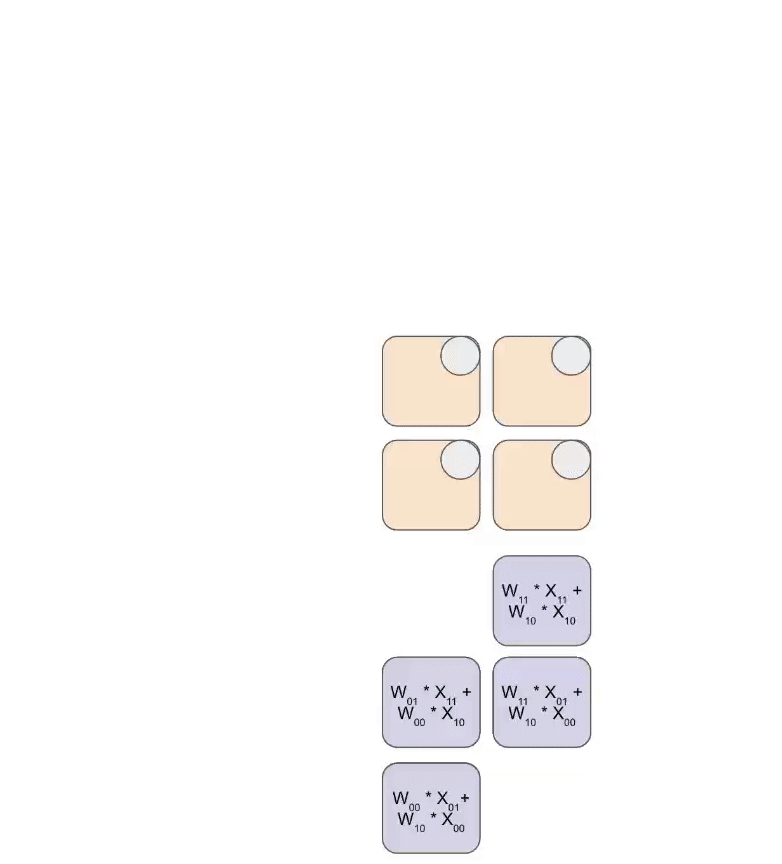 Animation showing systolic array operation: weights (blue) multiplied with activations (green). Source: How to Scale Your Model
Animation showing systolic array operation: weights (blue) multiplied with activations (green). Source: How to Scale Your Model
Efficiency Considerations
-
Dimension Requirements:
- Matrices must be padded to multiples of 128 (or 256 for TPU v6e)
- Smaller matrices waste MXU capacity (partial filling)
-
Pipelining:
- Initial pipeline bubble as weights and activations load
- Can be efficiently pipelined for subsequent operations
- Optimal for large batches that amortize the initial load cost
-
Memory Interaction:
- Reads input matrices from VMEM, not directly from HBM
- Outputs results to VMEM
- Efficient when computation time exceeds data transfer time