Roofline Model Fundamentals
When running algorithms on hardware, we’re bound by three fundamental constraints:
- Compute Speed: How fast the hardware can do math operations (FLOPs/second)
- Bandwidth: How quickly data can be moved around (bytes/second)
- Memory Capacity: Total available storage for data (bytes)
These “Roofline” constraints help us establish upper and lower bounds for computation time.
Time Estimation Formulas
Computation Time
Example:
Communication Time
Communication happens in two main contexts:
- Within a chip: Transfers between on-chip memory (HBM) and compute cores
- Between chips: When distributing models across multiple accelerators
Time Bounds
- Lower bound:
- Upper bound:
In practice, we optimize toward the lower bound by overlapping communication and computation.
Arithmetic-Intensity
Definition: The ratio of total FLOPs performed to the number of bytes communicated.
$\text{Arithmetic Intensity} = \frac{\text{Computation FLOPs}}{\text{Communication Bytes}}$$
This measure (FLOPs/byte) determines whether an operation will be compute-bound or communication-bound:
- High intensity: Fully utilizes available FLOPs (compute-bound)
- Low intensity: Wastes FLOPs while waiting for data (communication-bound)
The crossover point is the “peak arithmetic intensity” of the hardware:
For TPU v5e MXU, this is ~240 FLOPs/byte (1.97e14 FLOPs/s ÷ 8.2e11 bytes/s).
Example: Dot Product
For a dot product operation (x • y), where x and y are bfloat16 vectors of length N:
With an intensity of 0.5 FLOPs/byte, dot product operations are communication-bound on most hardware.
Visualizing Rooflines
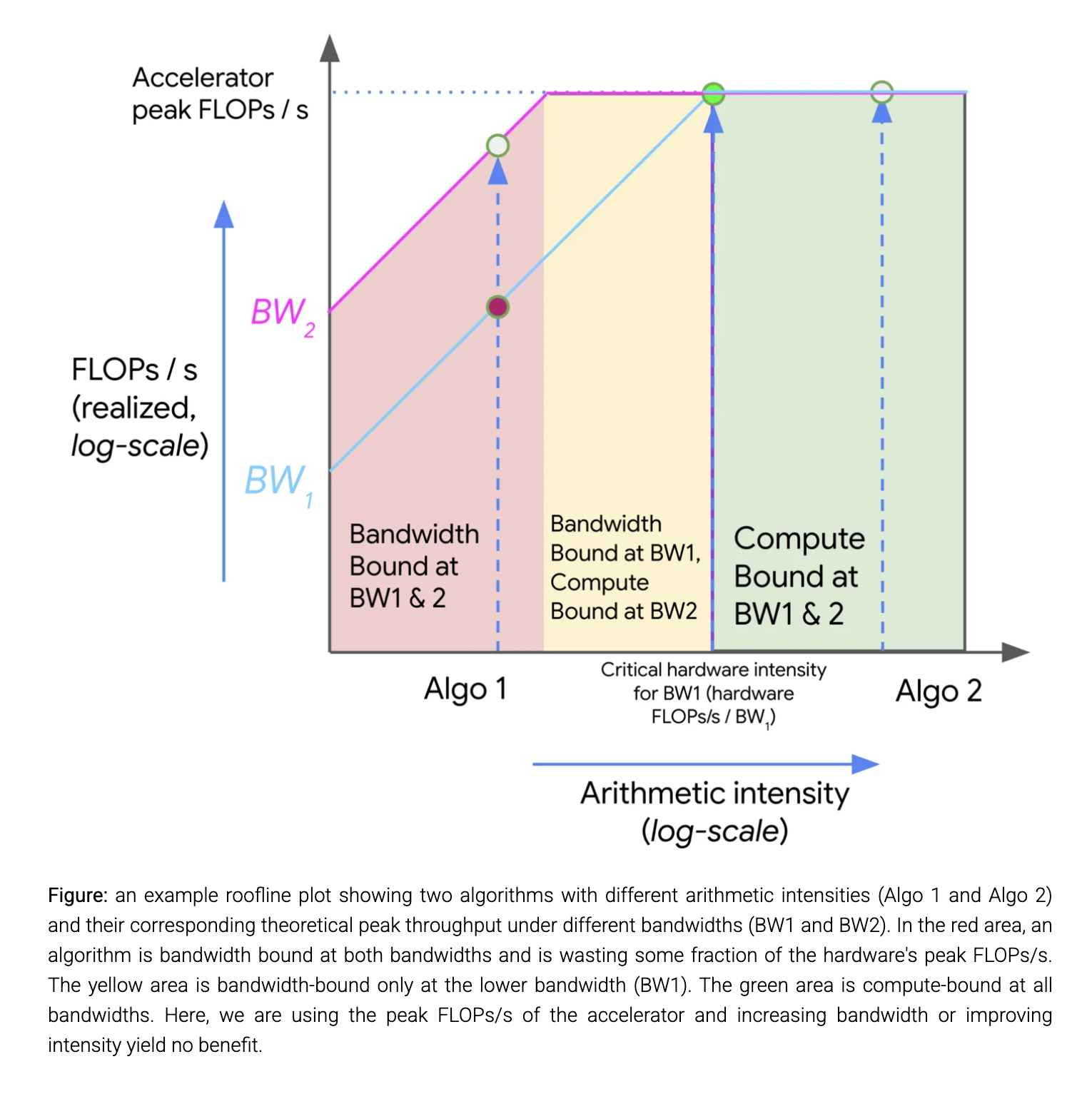 Source: How To Scale Your Model - Rooflines
Source: How To Scale Your Model - Rooflines
A roofline plot shows the relationship between arithmetic intensity (x-axis) and achievable performance in FLOPs/s (y-axis). The plot has three regions:
- Red area: Bandwidth-bound at all bandwidths
- Yellow area: Bandwidth-bound at lower bandwidths only
- Green area: Compute-bound at all bandwidths
Performance can be improved by:
- Increasing arithmetic intensity of algorithms
- Increasing available memory bandwidth
Matrix-Multiplication Analysis
For matrix multiplication X * Y → Z where:
- X has shape bf16[B, D]
- Y has shape bf16[D, F]
- Z has shape bf16[B, F]
When the local batch size B is small relative to D and F (typical in Transformers):
Key Takeaway
For a bfloat16 matrix multiplication to be compute-bound on most TPUs, the local batch size in tokens needs to be greater than 240 (~300 for GPUs)
Network Communication Rooflines
When matrices are split across multiple accelerators, we need to consider inter-chip communication rooflines.
e.g. For a matrix multiplication split across 2 TPUs:
- Each TPU does half the work:
- Communication time is:
The operation becomes compute-bound when: or
Unlike the single-chip case, the critical threshold depends on D, not B. Why?
Cause D is now no longer factors in the data being moved, but B and F still do. Since B and F are both a factor in # FLOPs and data being moved, only B determines bottleneck.