Apple Silicon Metal vs NVIDIA CUDA
Translate
| Metal Term | CUDA Equivalent | Description |
|---|---|---|
| GPU Core | Streaming Multiprocessor (SM) | Basic compute unit containing multiple ALUs, schedulers, and caches |
| Grid | Grid | Overall structure of work to be processed by the GPU |
| Threadgroup | Thread Block | Group of threads that can synchronize and share memory |
| Thread | Thread | Individual execution unit that processes a single element of work |
| SIMD-group | Warp | Group of 32 threads executed in lockstep |
| Threadgroup Memory | Shared Memory | Fast memory accessible by all threads in a threadgroup/block |
| Device Memory | Global Memory | Main GPU memory accessible by all threads |
| Constant Memory | Constant Memory | Read-only memory optimized for broadcast access |
| Texture Memory | Texture Memory | Specialized memory with spatial caching for image access |
| Command Buffer | CUDA Stream | Sequence of commands executed in order |
| Command Queue | CUDA Context | Container for scheduling command buffers/streams |
| Compute Pass | Kernel Launch | Execution of a function on the GPU |
| Metal Kernel | CUDA Kernel | Function executed in parallel on the GPU |
| Threadgroup Barrier | __syncthreads() | Synchronization point for all threads in a threadgroup/block |
| SIMD-group Barrier | __syncwarp() | Synchronization within a warp/SIMD-group |
| Memory Fence | Memory Fence | Ensures memory operations are visible to other threads |
| Device Function | Device Function | Helper function called by kernels, executed on GPU |
| Buffer | Memory Pointer | Reference to allocated memory |
| MTLSize | dim3 | 3D structure for specifying dimensions |
| Argument Buffer | Kernel Parameters | Way to pass structured data to kernels |
| Threadgroup Size | Block Dimensions | Number of threads in each threadgroup/block |
| Grid Size | Grid Dimensions | Number of threadgroups/blocks in the grid |
| Metal Compute Pipeline | CUDA Module/Program | Compiled GPU code ready for execution |
| simdgroup_shuffle() | __shfl() | Exchange values between threads in a SIMD group/warp |
| Metal Heap | CUDA Memory Pool | Allocation mechanism for device memory |
| Indirect Command Buffer | CUDA Graph | Precompiled sequence of commands for repeated execution |
-
Sync threads in a threadgroup/block:
-
threadgroup_barrier(mem_flags::mem_none)=__syncthreads(); -
Create shared
-
threadgroup=__shared__
Architecture of a CUDA Capable GPU
Architecture of a Metal Capable GPU
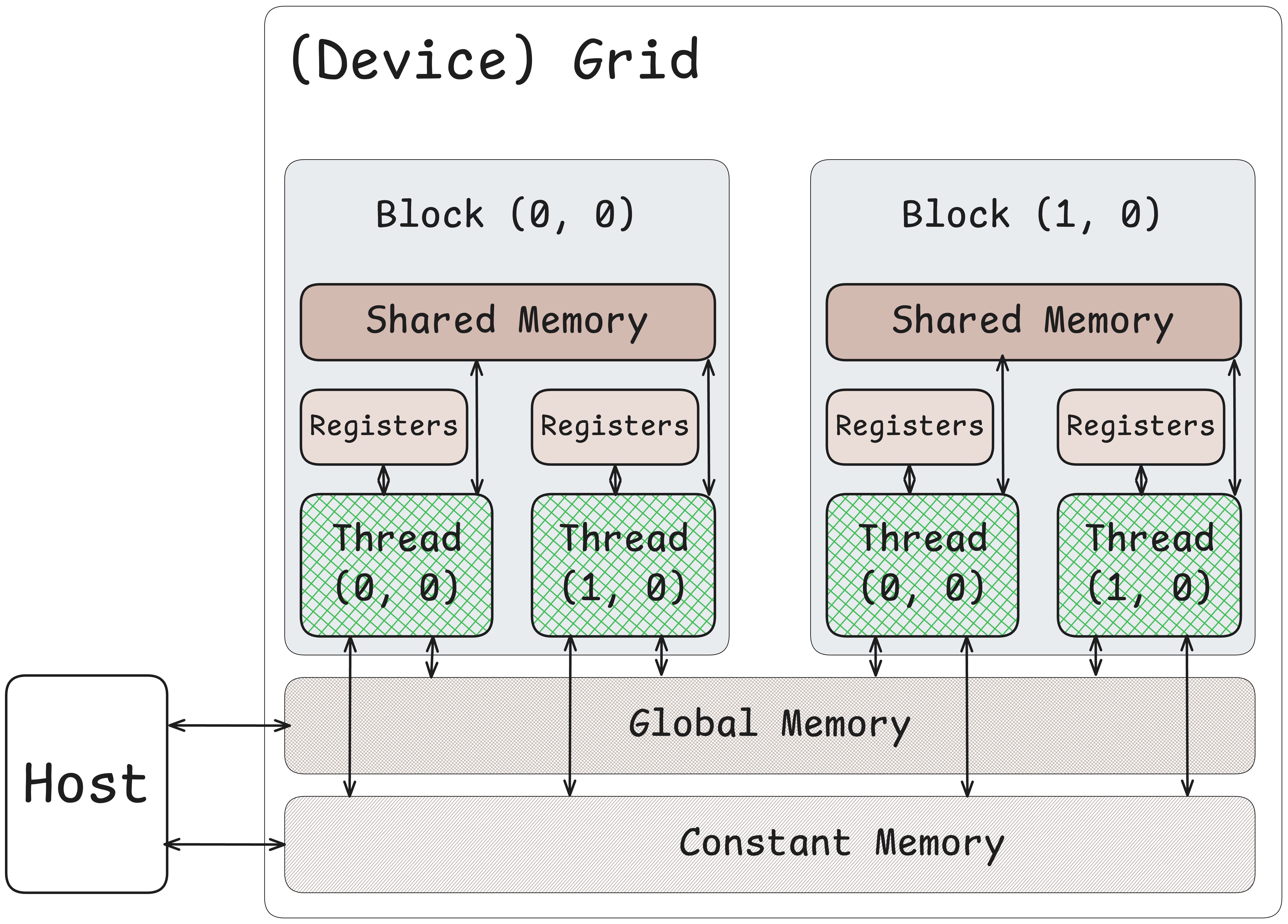
CUDA Device Memory Model
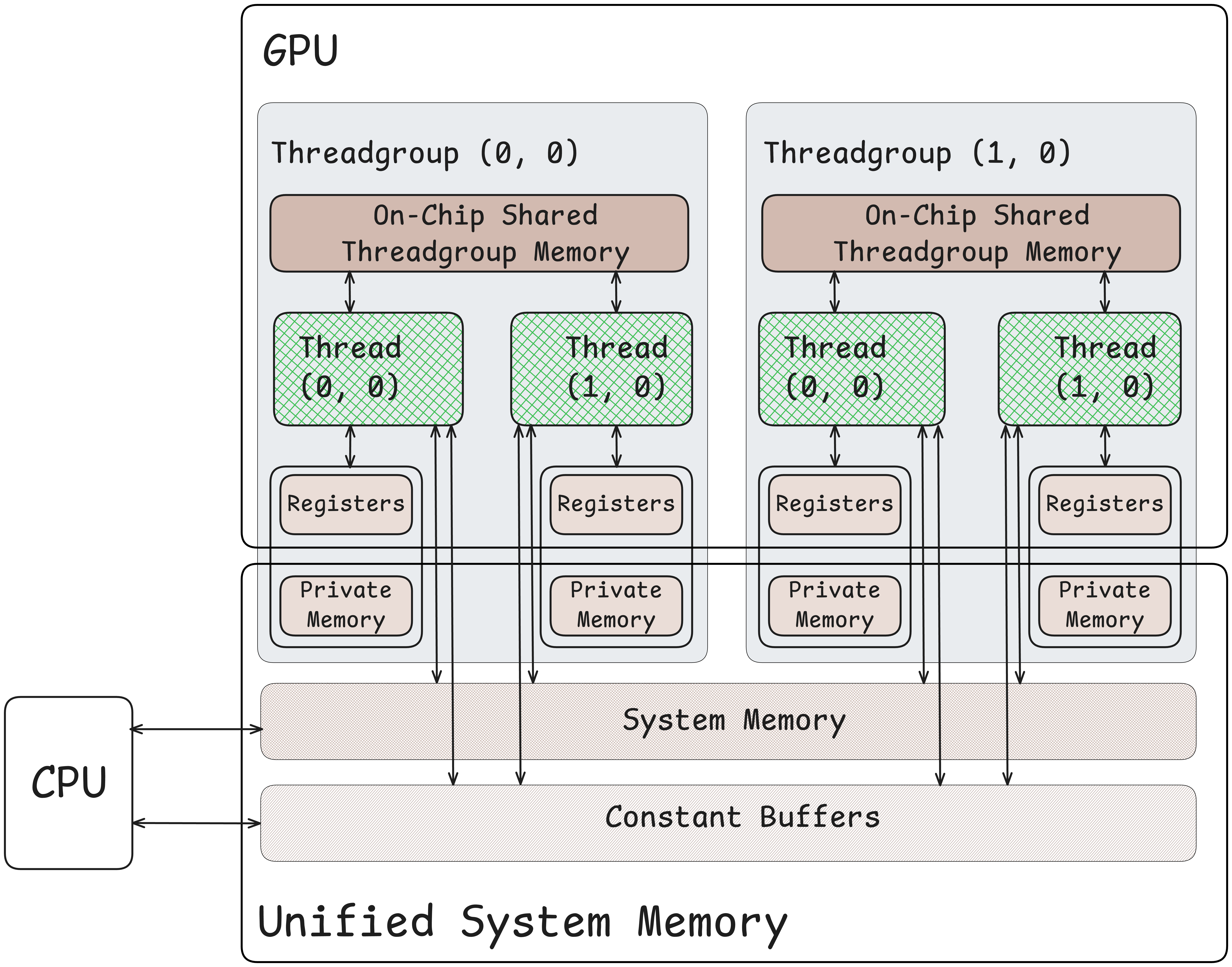
Apple Silicon GPU Memory Model
| Feature | NVIDIA RTX 3090 (Ampere) | Apple M1 Max |
|---|---|---|
| Warp/SIMD Size | 32 threads per warp | 32 threads per SIMD-group |
| Execution Model | SIMT – each thread has its own context | SIMD – 32 lanes share one instruction stream |
| Compute Units | 82 Streaming Multiprocessors (SMs) | 32 GPU cores |
| ALUs per Compute Unit | 128 FP32 ALUs per SM + 4 Tensor Cores | 128 ALUs per core |
| Total ALUs | ~10,496 FP32 ALUs | ~4,096 ALUs |
| Clock Frequency | 1.7 GHz (boost up to 1.8 GHz) | 1.3 GHz |
| Theoretical FP32 Performance | 35.6 TFLOPS | 10.4 TFLOPS |
| Low-Precision Math | FP16: 71.2 TFLOPS (via Tensor Cores) | FP16: 10.4 TFLOPS (no acceleration) |
| Shared Memory per Block/Group | 48 KB configurable | 32 KB |
| L1 Cache per Compute Unit | 128 KB per SM | 32 KB per core |
| L2 Cache | 6 MB total | 24 MB System Level Cache (shared) |
| Memory | 24 GB GDDR6X (dedicated) | Up to 64 GB unified LPDDR5 |
| Memory Bandwidth | 936 GB/s (384-bit bus) | 400 GB/s (512-bit bus) |
| TDP | 350W | 60W (entire SoC including CPU) |
| Max Threads Per Block/Group | 1024 threads | 1024 threads |
| Thread Dimensions | 1024 × 1024 × 64 | 1024 × 1024 × 1024 |
| Grid/Dispatch Dimensions | 2³¹-1 × 65535 × 65535 | 2³²-1 × 65535 × 65535 |
| Registers Per Block/Group | 65536 | 65536 |
| Max Blocks Per Compute Unit | 16 blocks per SM | 24 threadgroups per core |
| Registers Per Thread | Up to 255 | Up to 128 |