Sharding Matrices
When training large models across many TPUs, we need to split up arrays that don’t fit in the memory of a single accelerator. This process is called sharding or partitioning.
Partitioning Notation
A sharded array has two important shapes:
- Global/logical shape: The total shape of the unsharded array
- Device local shape: The actual size that each device holds
Device Mesh and Named-Axis Notation
We use a variant of named-axis notation to describe how tensors are sharded across devices:
- Device Mesh: A 2D or 3D grid of devices with assigned mesh axis names (X, Y, Z)
- Sharding: Assignment of tensor dimensions to mesh axes
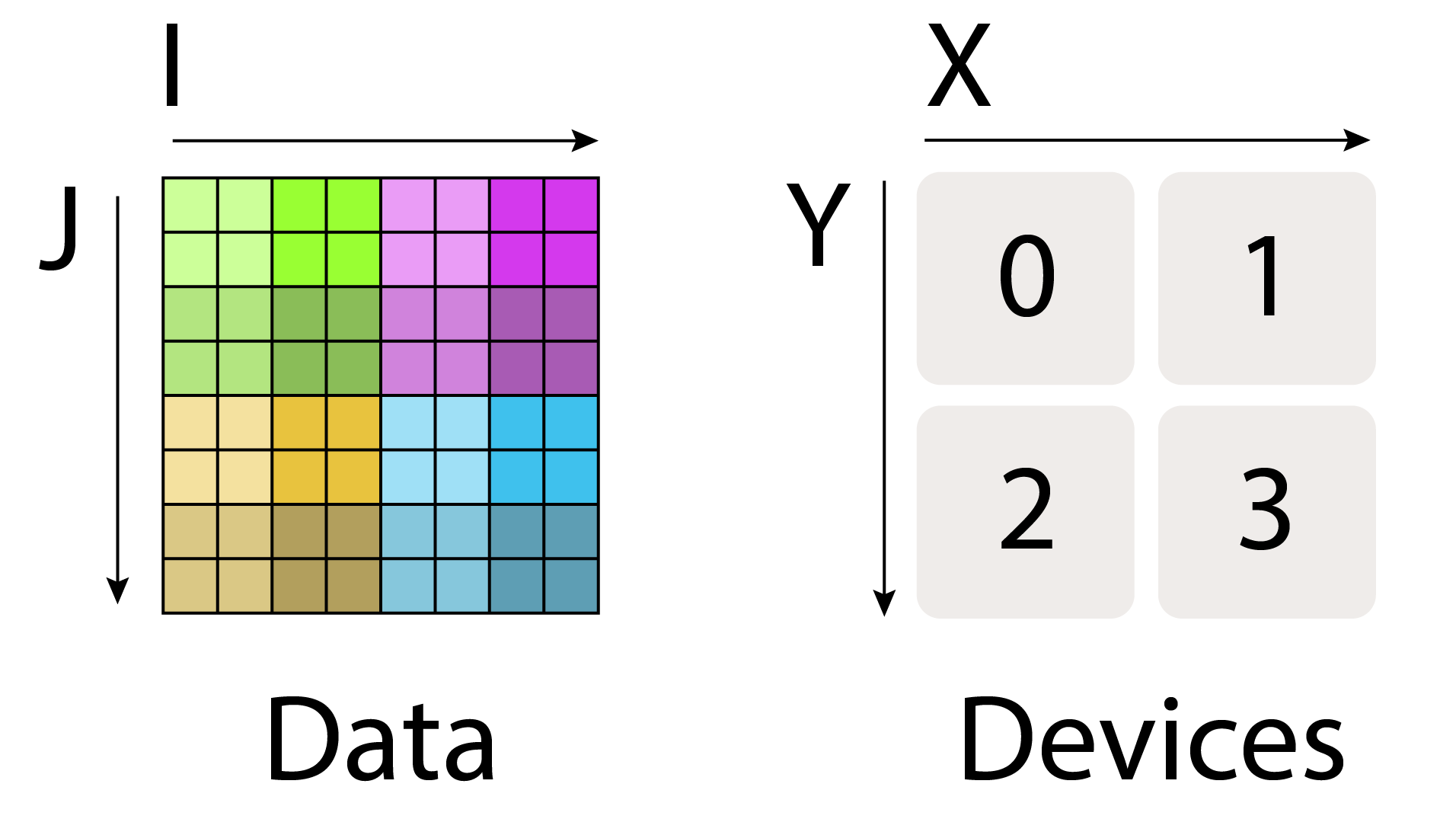 Figure: Axes notations used for data and mesh (in this book). Source: How to Scale Your Model
Figure: Axes notations used for data and mesh (in this book). Source: How to Scale Your Model
Sharding Notation Examples
- A[I, J]: Fully replicated (each device has a complete copy)
- A[IX, J]: First dimension sharded along X mesh axis, second dimension replicated
- A[IX, JY]: First dimension sharded along X, second along Y
- A[IXY, J]: First dimension sharded along both X and Y (flattened)
The local shape depends on the global shape and sharding pattern. For example, with A[IX, JY], each device’s local shape is (|I|/|X|, |J|/|Y|).
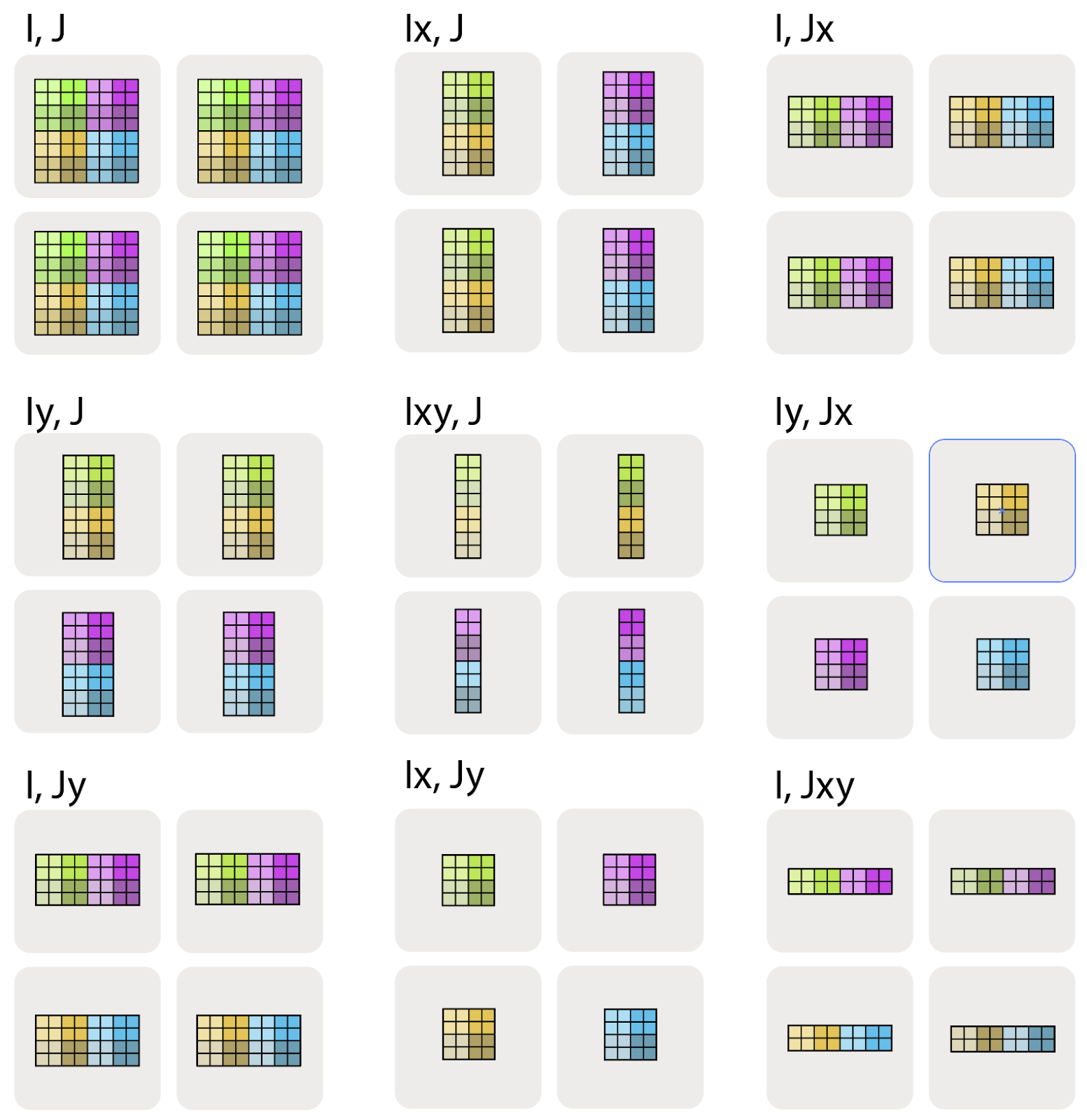 Figure: Sharding configurations for a 2D matrix along a 2D mesh. Source: How to Scale Your Model
Figure: Sharding configurations for a 2D matrix along a 2D mesh. Source: How to Scale Your Model
[! Important] We cannot have multiple dimensions sharded along the same mesh axis e.g., A[IX, JX] is invalid
JAX sharding example
import jax
import jax.numpy as jnp
import jax.sharding as shd
# Create our mesh! We're running on a TPU v2-8 4x2 slice with names 'X' and 'Y'.
assert len(jax.devices()) == 8
mesh = jax.make_mesh(axis_shapes=(4, 2), axis_names=('X', 'Y'))
# A little utility function to help define our sharding. A PartitionSpec is our
# sharding (a mapping from axes to names).
def P(*args):
return shd.NamedSharding(mesh, shd.PartitionSpec(*args))
# We shard both A and B over the non-contracting dimension and A over the contracting dim.
A = jnp.zeros((8, 2048), dtype=jnp.bfloat16, device=P('X', 'Y'))
B = jnp.zeros((2048, 8192), dtype=jnp.bfloat16, device=P(None, 'Y'))
# We can perform a matmul on these sharded arrays! out_shardings tells us how we want
# the output to be sharded. JAX/XLA handles the rest of the sharding for us.
compiled = jax.jit(lambda A, B: jnp.einsum('BD,DF->BF', A, B), out_shardings=P('X', 'Y')).lower(A, B).compile()
y = compiled(A, B)Computing with Sharded Arrays
Elementwise Operations
Elementwise operations on sharded arrays have no communication overhead – each device can operate independently on its local portion.
Matrix Multiplication with Sharded Arrays
Matrix multiplication between sharded arrays requires different communication patterns depending on how the arrays are sharded. There are four key cases:
Case 1: No Sharded Contracting Dimensions
When neither multiplicand has a sharded contracting dimension, we can multiply local shards without any communication:
This works because the computation is independent of the sharding - each device has the complete data it needs for its portion of the output.
All of these cases follow this rule:
Case 2: One Sharded Contracting Dimension
When one multiplicand has a sharded contracting dimension, we typically perform an AllGather operation:
First, gather all shards of A:
Then multiply the fully gathered matrices:
Case 3: Both Inputs Have Sharded Contracting Dimensions
When both inputs are sharded along the contracting dimension:
We can:
- Multiply local shards to get partial sums:
- Perform an AllReduce to sum the partial results:
Alternatively, we can use ReduceScatter followed by AllGather:
Case 4: Invalid Sharding Pattern
When both multiplicands have a non-contracting dimension sharded along the same axis:
This is invalid because each device would only compute a diagonal entry of the result.
To resolve this, we must AllGather one of the inputs first:
or:
Communication Primitives
Core Communication Operations
TPUs use four fundamental communication primitives for distributed computation:
- AllGather: Removes a subscript from a sharding by collecting shards
- Syntax:
- ReduceScatter: Removes an “unreduced” suffix by summing shards over that axis
- Syntax:
- AllReduce: Removes an “unreduced” suffix without introducing new sharding
- Syntax:
- Can be composed as ReduceScatter + AllGather
- AllToAll: Switch shard from one axis to the other in the mesh
- Syntax:
 Figure: Visual representation of the four communication primitives
Figure: Visual representation of the four communication primitives
Source: How to Scale Your Model
Communication Cost Analysis
For bandwidth-bound operations, the cost of communications depends on:
- The size of the input arrays
- The bandwidth of the links
- The communication primitive being used
| Operation | Description | Runtime |
|---|---|---|
| AllGather | Gathers shards of an array | bytes / (bidirectional bandwidth * num_axes) |
| ReduceScatter | Sums partial results and reshards | Same as AllGather |
| AllReduce | Sums partial results without resharding | 2 * AllGather |
| AllToAll | Transposes sharding between dimensions | AllGather / 4 (on bidirectional ring) |
The cost of these operations does not depend on the number of devices (in bandwidth-bound regime), but only on the data volume and available bandwidth.
ReduceScatter in Backpropagation
An important relationship: ReduceScatter is the gradient operation of AllGather:
- If the forward pass has:
- Then backward pass has:
This relationship is critical for understanding communication patterns in backward passes during training.